Sun, Nov 27, 2011, 7:19pm
Journal Article Reading / Tracking
Programming

T
here are times when (a) I'd rather use a Terminal shell to search for something, or it's already where I am, and (b) when I'm in the mood to write a little set of scripts to do something neat. And so it came that I wrote a set of little scripts to keep track of my completely out-of-control PDF collection from various journals. This isn't a blog article about how you should use this tool, since your reading neuroses probably differ, but just a quick "hey, I think this is neat" and something that may inspire someone on to other cool command-line tools (or whatnot).
I have a tremendous amount of articles in the area of history and philosophy of science which I'm going through roughly in order of when the articles were written. I have them in a "Journals" folder, where I have the name of the journal as a folder, followed by folders for each volume / year, followed by the articles themselves. (Sometimes it's more complicated.) So, for example:

As shown, I also label files "(pages) Article Title — Author(s)". All folders include the year(s).
When I've read an article, I use Finder labels to colorize the file blue for "I've read this" and grey for "reference only". Unlabeled pdfs are things I'd like to read at some point. (There are too many articles for me to usefully use a color for items that are more pressing than others.)
So, the search I created, "unread", takes a year or span of years and displays all to-be-read articles.
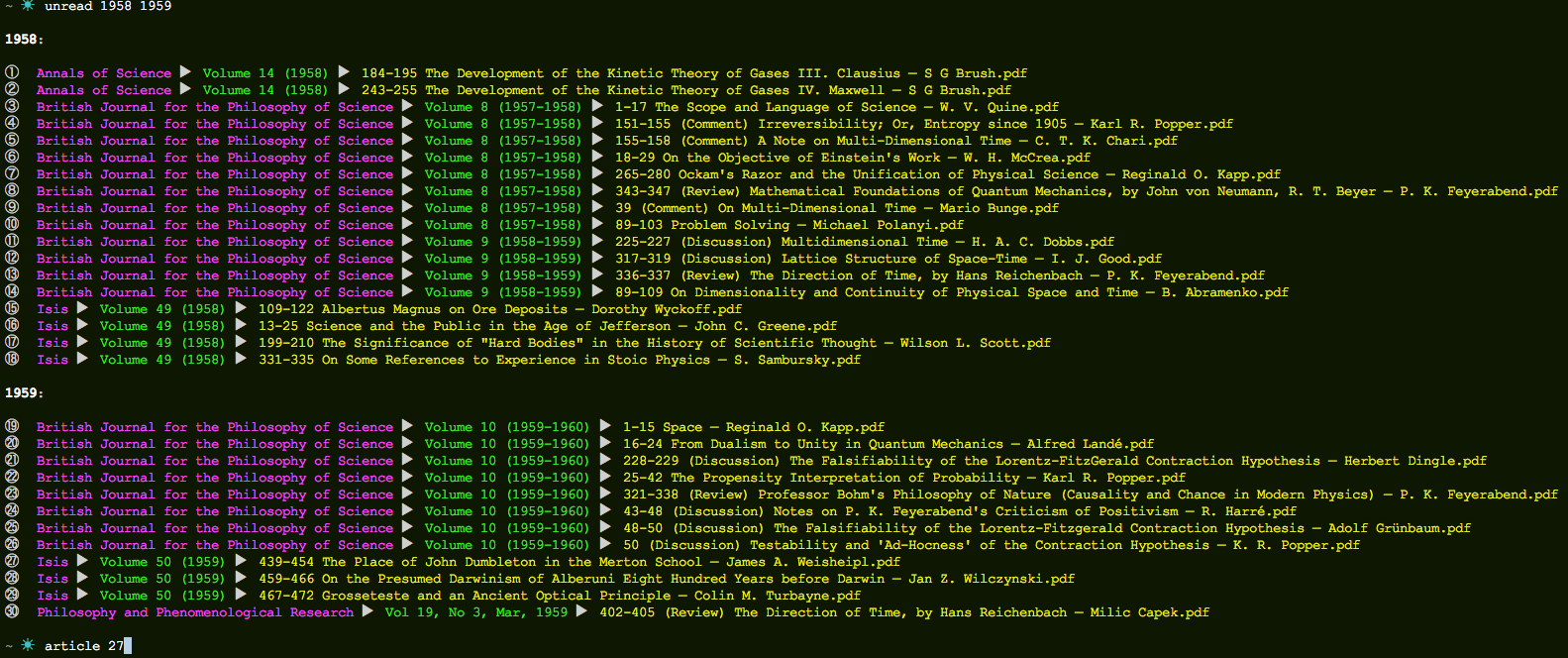
I use the command-line spotlight command, mdfind, twice. Once to find folders with the years for my search, and then again to find files that have no label within those folders. The results are parsed to look pretty at the command line and also saved inside a ~/.unread file. Each displayed file name is given a number. One can then use a second command, "article", to open that article with the default reader.
Here is an example search. Terminal colors and unicode help make it more palatable to the eyes.
Seems perhaps too simple to be worth implementing. But I have found that I have become much more efficient in my article reading, in a way that I think a dedicated GUI program would be overkill for, and perhaps itself too distracting. I can also use "unread" over any ssh connection back to my main archives. (Many GUI programs like to handle file naming on their own, something I find intolerable.)
I have a final command called "markArticle" that sets an article as having been read. Ex: "markArticle 14 15 21". So, the full set of tools is:
unread (year(s)) article (article number(s)) markArticle (article(s))
Ok, that's it. Just having fun. Back to reading.
I have a tremendous amount of articles in the area of history and philosophy of science which I'm going through roughly in order of when the articles were written. I have them in a "Journals" folder, where I have the name of the journal as a folder, followed by folders for each volume / year, followed by the articles themselves. (Sometimes it's more complicated.) So, for example:
As shown, I also label files "(pages) Article Title — Author(s)". All folders include the year(s).
When I've read an article, I use Finder labels to colorize the file blue for "I've read this" and grey for "reference only". Unlabeled pdfs are things I'd like to read at some point. (There are too many articles for me to usefully use a color for items that are more pressing than others.)
So, the search I created, "unread", takes a year or span of years and displays all to-be-read articles.
I use the command-line spotlight command, mdfind, twice. Once to find folders with the years for my search, and then again to find files that have no label within those folders. The results are parsed to look pretty at the command line and also saved inside a ~/.unread file. Each displayed file name is given a number. One can then use a second command, "article", to open that article with the default reader.
Here is an example search. Terminal colors and unicode help make it more palatable to the eyes.
Seems perhaps too simple to be worth implementing. But I have found that I have become much more efficient in my article reading, in a way that I think a dedicated GUI program would be overkill for, and perhaps itself too distracting. I can also use "unread" over any ssh connection back to my main archives. (Many GUI programs like to handle file naming on their own, something I find intolerable.)
I have a final command called "markArticle" that sets an article as having been read. Ex: "markArticle 14 15 21". So, the full set of tools is:
Ok, that's it. Just having fun. Back to reading.