Tue, Feb 26, 2008, 3:43am
First dip into the OpenMP world
Programming » OpenMP
(Last updated: Tue, Mar 4, 2008, 4:27pm)
S
o my first bit of fun in OpenMP land was adding one line to a C program that just multiplies a n-by-m matrix with an n-vector. It's the first example program in the Using OpenMP book I'm reading. It's just a basic hello-world-type program, but it's important to get that first program compiled and running. The listing is here, which is only a slight deviation from what's in the book.
I ran the program and put in just random sizes for n and m and found while my program did get all the cores cranking on the problem, the results were often much worse than if I did nothing at all. I puzzled over that a bit. I knew that there's some overhead with all this forking and joining of threads, but then the answer hit me. The parallel part of the code is during the looping of the rows and columns of the matrix. If the matrix and/or vector dimensions are small, then one is giving several threads short bits of work and then joining, and doing this a bunch of times. The parallelization would work best of you have a lot of ns or ms to work with. When I cranked up those numbers, I saw that the program really did produce better results in those cases.
And then I wanted to see how many threads is worth the effort here, since just letting your program wail away on all cpu cores might not create the most user-friendly experience unless the return on investment is sufficiently high, or if the user says it's ok. (I'm looking ahead to friendly ways any parallel program can work within a user's environment. It might not be the right thing to assume it's ok to use all resources available at all times.) Simply setting OMPNUMTHREADS in the shell environment allows me to set this to whatever I need, so I used the shell's time command to grab some empirical performance data, something I want to get used to doing.
I used PyLab to let me whip up some nice graphs (I could also post that code if others are interested), letting OMPNUMTHREADS vary from 1 to 8 (even though 1 just means adding overhead with no expected gain). (I kept things simpler by making n and m have the same value.) I ran the program to loop 1000 times over the calculation, or else it happens too quick. Here's what I came up with:
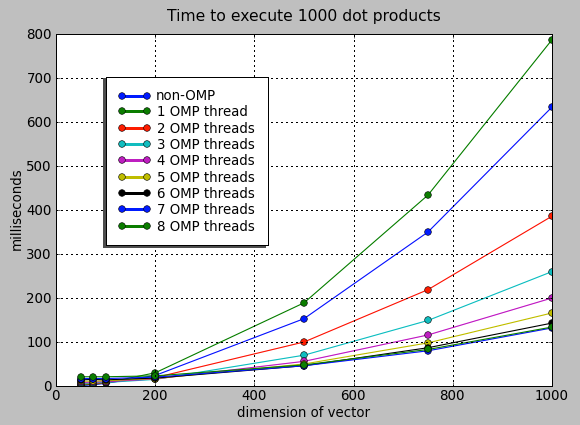
As expected 1 OMP thread is worse than no OMP, but it's interesting that OpenMP in general only gave me gains after n=m=200 or so, a bit larger than I expected, which is probably why my first few trial runs gave me the unexpectedly bad results. Here's a close-up of the cross-over point:
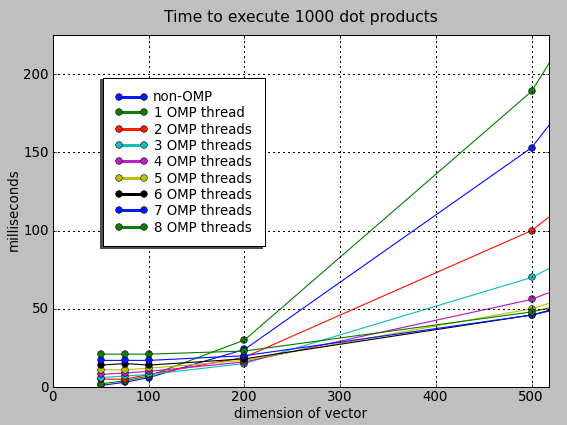
Anything below about n=m=150, don't bother. This will be my lesson to always test the real effects of these tricks to know whether or not (and how) to use this stuff. After about 225, it's all gravy. Note that 3 to 5 threads seems to account for most of all the gains. After that point, using more CPUs should only be done if the user has requested the program to go full blast. Also, the more threads, the higher the overhead, the larger the vector/matrix needed to be before its benefits were obvious.
On a consumer machine, even one being used for scientific computation, the user still could be watching a movie, compiling something in the background, have a hundred Safari windows open, etc etc, and since OpenMP makes it so easy to throttle the threading, why not.
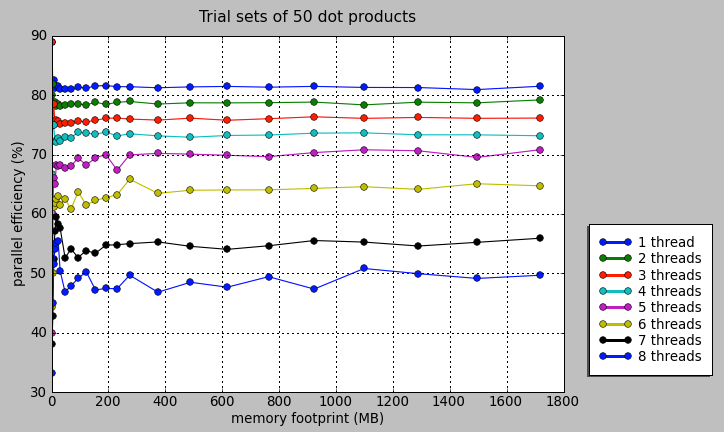
Update 3/4: I expanded the data set size as far as my machine would let me to find out if this program would produce super-linear behavior for some memory sizes, as happens in the Using OpenMP book, but found nothing so fun:
My machine specs for this test: MacPro 8-core, 3GHz Xeon, 7G RAM, GCC 4.3.0.
I ran the program and put in just random sizes for n and m and found while my program did get all the cores cranking on the problem, the results were often much worse than if I did nothing at all. I puzzled over that a bit. I knew that there's some overhead with all this forking and joining of threads, but then the answer hit me. The parallel part of the code is during the looping of the rows and columns of the matrix. If the matrix and/or vector dimensions are small, then one is giving several threads short bits of work and then joining, and doing this a bunch of times. The parallelization would work best of you have a lot of ns or ms to work with. When I cranked up those numbers, I saw that the program really did produce better results in those cases.
And then I wanted to see how many threads is worth the effort here, since just letting your program wail away on all cpu cores might not create the most user-friendly experience unless the return on investment is sufficiently high, or if the user says it's ok. (I'm looking ahead to friendly ways any parallel program can work within a user's environment. It might not be the right thing to assume it's ok to use all resources available at all times.) Simply setting OMPNUMTHREADS in the shell environment allows me to set this to whatever I need, so I used the shell's time command to grab some empirical performance data, something I want to get used to doing.
I used PyLab to let me whip up some nice graphs (I could also post that code if others are interested), letting OMPNUMTHREADS vary from 1 to 8 (even though 1 just means adding overhead with no expected gain). (I kept things simpler by making n and m have the same value.) I ran the program to loop 1000 times over the calculation, or else it happens too quick. Here's what I came up with:
As expected 1 OMP thread is worse than no OMP, but it's interesting that OpenMP in general only gave me gains after n=m=200 or so, a bit larger than I expected, which is probably why my first few trial runs gave me the unexpectedly bad results. Here's a close-up of the cross-over point:
Anything below about n=m=150, don't bother. This will be my lesson to always test the real effects of these tricks to know whether or not (and how) to use this stuff. After about 225, it's all gravy. Note that 3 to 5 threads seems to account for most of all the gains. After that point, using more CPUs should only be done if the user has requested the program to go full blast. Also, the more threads, the higher the overhead, the larger the vector/matrix needed to be before its benefits were obvious.
On a consumer machine, even one being used for scientific computation, the user still could be watching a movie, compiling something in the background, have a hundred Safari windows open, etc etc, and since OpenMP makes it so easy to throttle the threading, why not.
Update 3/4: I expanded the data set size as far as my machine would let me to find out if this program would produce super-linear behavior for some memory sizes, as happens in the Using OpenMP book, but found nothing so fun:
My machine specs for this test: MacPro 8-core, 3GHz Xeon, 7G RAM, GCC 4.3.0.